“存算分离”已成趋势,曙光存储发布面向金融的可信AI存储方案
信创与AI应用,一边是关于自主可控,一边是关于智慧化转型,均是当下金融业的热门话题。
在金融机构客观需要的同时,金融监管层面非常支持金融机构推进信创与AI应用。2024年,监管提出要求,到2027年金融机构所有系统实现信创化,2028年实现包括核心系统在内的全系统的单轨运行,不能保留原来的技术栈。2025年5月,人民银行科技司司长李伟撰文指出,稳妥有序推进金融领域人工智能大模型应用;同月,金融监管总局局长李云泽也强调,稳妥推进人工智能在金融领域的应用。
金融机构积极响应,掀起了“声势浩大”的信创深化、AI应用热潮。在此过程中,技术架构从“存算一体”升级至“存算分离”的讨论声音越来越多。
金融信创、AI应用背后,数据库瓶颈与数据治理问题凸显
金融机构推进信创以及AI应用的热情,悉数体现在最新报告中。
信创方面:
今年发布的《数字经济与数字金融形势分析》报告显示,我国金融信创进入应用深化和生态建设阶段。报告指出,技术生态逐步成熟,推动金融信创替换路径从外围边缘系统深入内部核心系统,改造场景从一般业务系统深入金融核心系统。国产数据库产品逐步在金融交易系统、数据仓库等场景替代国外数据库并形成规模化效应。
第一新声智库最近发布的《2025年中国金融业数据库国产替代能力评估报告》则显示,当前金融业数据库国产替代呈现以下特征:大型金融机构核心系统替换加速,中小金融机构依旧是替代主力。
AI应用方面:
腾讯研究院与毕马威联合发布的《2025金融业大模型应用报告》提到,全球近半数金融机构已启动大模型应用建设,行业正从零星的试验阶段迈入规模化部署期。中国金融业的大模型建设呈现出顶层设计、梯次推进的清晰格局:银行业是大模型落地应用最广泛的领域,证券、保险行业的头部机构则作为先行者,探索出多样化的应用模式。
推进信创、加速AI应用是金融业的2大趋势。趋势不可阻挡,挑战也随之而来——在这背后,数据库“瓶颈”与数据治理难题浮出水面。
据悉,金融机构前期一般采用“服务器本地盘多副本+信创分布式数据库”架构,这种架构在当下正面临多重挑战,包括但不限于:
数据安全风险问题。计算与存储节点的强耦合,导致数据暴露面过大、数据与计算无差别共存,难以满足监管要求。
运维复杂性问题。软硬件高度绑定,故障排查困难。无论是出现磁盘故障时,还是对存储空间进行扩容,甚至是日常的维护与变更,都显得难以下手。
存储空间利用率问题。在多副本存储策略之下,为保证数据的可靠性,需占用更多存储空间。
数据一致性问题。在分布式环境中,多个节点对数据进行读写操作时,网络延迟、节点故障等因素可能导致数据副本间出现差异,且多副本策略虽能提高容错性,但需要复杂算法确保一致性,如此会增加相关开销、降低性能。
TWT技术社区用户在讨论中就印证了上述问题。例如,某城商行存储架构师表示,信创分布式数据库大多采用服务器本地盘+副本模式,虽提高了数据冗余性,但牺牲了部分空间且容量使用率低,对于介质故障主要依靠数据副本重构;某股份制银行存储架构师则指出,服务器本地盘是固定槽位数量,容量的纵向扩容就需要扩多个数据库节点,实施复杂度高。
另外,AI的大规模应用,对数据治理能力提出了更高要求。银行关键OLTP交易系统产生的数据,是AI模型极其重要的“养料”,可支撑智能风控、智能营销等场景,但作为敏感数据,必须确保其安全地汇入AI数据湖;其次,数据量和交互频率大幅增加,网络延迟、带宽限制等因素会影响数据读写性能;最后,数据同步延迟在高并发的AI训练、推理场景下会导致数据不一致,影响模型训练准确性和推理结果可靠性等。
因此,真正的“存算分离”架构——以专业的SAN存储对接信创分布式数据库,正引起金融业的关注。
对于“存算分离”,或许可以通过一个通俗的例子来理解。一个企业老板,若将视频拍摄(存)和视频剪辑(算)2项工作交给剪辑师,剪辑师“身兼多职”,压力大,同时在视频拍摄上不够专业,可能易导致其崩溃(系统不够稳定可靠)。若老板再引入一个摄影师(专业存储),将视频拍摄的工作交给专业的人负责,不仅能提升2人的效率,而且在双方的配合下,视频质量也会提高。
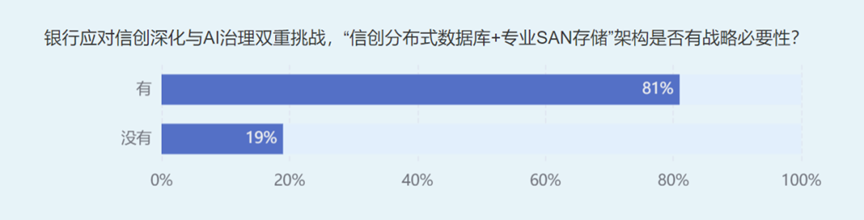
在TWT技术社区近期发布的专题投票中,有81%的用户认为真正的存算分离架构具有战略必要性,即信创分布式数据库+专业SAN存储架构。
上述某股份制银行存储架构师进一步表示,外置存储策略下,无需配置较多数据库节点,按需从存储上分配容量即可。此外,从运维角度来说,存算分离减少了设备数量,一方面降低了设备投入和机房机柜成本,另一方面也降低了运维复杂度。某大型金融企业系统架构师提到,对于需要处理大量并发读写请求的业务,在面对海量数据存储和高效访问需求的场景下,专业SAN存储+信创分布式数据库的方案能够提供较高的并发处理能力和快速的IO响应速度,满足业务对性能的要求。
“存算分离”成业界共识,曙光存储顺势发布面向金融的可信AI存储方案
事实上,从数据本身来说,这个时代的数据如同工业时代的石油,其重要性不言而喻,而伴随而来的数据存储当然不容忽视。
在前几年,“数据存力”的概念被提出,以存储容量为核心,包含性能表现、可靠程度、绿色效能在内的综合体现定义数据存力,这使得数据存储受到更多关注。
早年已有文章指出,“计算和存储分离”是互联网和云计算巨头共同的选择,并成为近年数据库改造的流行趋势之首。
尤其是对于金融机构来说,金融业务对数据一致性、可靠性和稳定性有着极致要求,“信创分布式数据库+专业SAN存储”是更优解。AI时代更是如此,数据库存算分离架构带来算力与存力的灵活扩缩容能力,可更好地匹配AI场景对计算和存储资源需求不同步的特性。
那么,在拥抱存算分离架构,深化数据库与存储合作成为行业共识的当下,选择优秀的存储合作伙伴是非常重要的。
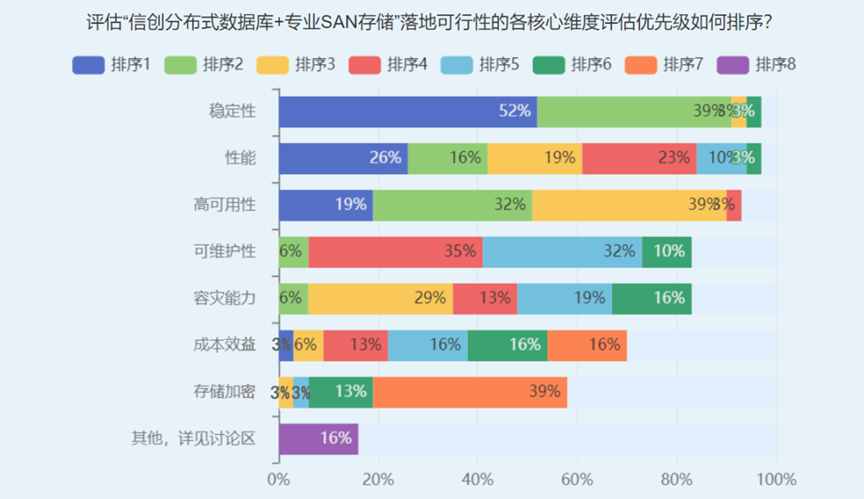
TWT技术社区的专题投票显示,对于存算分离架构,用户最关注稳定性、性能和高可用性这3个维度。
就在近日,曙光存储发布了面向金融业的可信AI存储方案,在这3个维度上有着不错的表现。
据《银行科技研究社》了解,该方案即借助曙光集中式全闪存储FlashNexus作为企业级SAN存储,对接分布式数据库,将“服务器本地盘多副本+信创分布式数据库”架构,替换为“专业SAN存储+信创分布式数据库”架构,实现真正的存算分离。

作为架构基石,集中式全闪存储FlashNexus在验证测试中可提供超200万IOPS(3个25盘位盘框组网时),满足绝大多数事务处理(TP)类业务的性能需求。
更重要的是,曙光的可信AI存储方案,可解决传统架构中的“痛点”,为金融机构推动AI大范围落地提供保障。
首先,数据获取不及时、不完整是很多企业数据治理上的一大问题,数据同步存在延迟将无法支撑金融机构风控、营销等模型的及时更新。曙光FlashNexus存储凭借其匹配金融核心业务的数据安全性与稳定低时延,可确保信创数据库产生的数据能够“秒级”同步至数据湖,让性能不再成为瓶颈。如此,最新产生的数据将能近乎实时地用于风控、营销等领域,有利于提升机构的竞争力。
其次,对于服务器本地盘多副本+分布式数据库架构所面临的数据不一致问题,曙光存储对接分布式数据库可从根本上进行解决,确保数据的高可用。曙光存储作为单一可信的数据源,通过其强大的多控、企业级高级数据保护技术,为数据库提供强一致性保证。该方案能保证汇入AI数据湖的每一个数据点均精准无误,让金融机构在风控、营销方面实现公平与准确。
最后,曙光存储+分布式数据库的架构可实现极致的敏捷性,进而解决用户对于稳定性的顾虑。试想,在传统架构下,企业为AI进行一次大规模训练,需要临时扩容较大的存储空间,此时要大费周章,扩容大量数据库服务器,时间、精力成本不低。而在存算分离架构下,计算与存储“井水不犯河水”,可分别扩展,如同“拧水龙头”一般收放自如。从传统架构下的“匆匆忙忙、连滚带爬”转到存算分离下的“从从容容、游刃有余”,按需为AI训练分配存储资源,有利于降低AI试错成本,加快AI落地应用。
某金融企业系统架构师表示,借助SAN存储自带的RAID、双控、快照、复制等能力,实现数据层面的高可用与容灾;这种方案最适合对数据一致性、可靠性要求极高且已有SAN存储基础环境的中大型企业,尤其是银行、保险、证券这类行业的关键业务系统。
据悉,在此之前,曙光存储的方案已在相关测试中取得了“亿点点”好成绩。2025年2月25日,国际存储性能委员会(SPC)公布SPC-1 V3基准测试结果,搭载最新一代国产处理器的曙光存储FlashNexus以32控架构、超3000万IOPS性能及0.202ms时延登顶全球榜首。这一成绩,标志着国产存储在核心场景应用能力的全面提升。
具体到金融业务场景,曙光存储已与多家信创分布式数据库进行了深度适配。在与东方国信、南大通用、平凯数据库的适配测试中,曙光存储全面完成了兼容性互通测试。而在江海证券的全项测试验证中,FlashNexus通过了高频交易、突发故障、高并发复杂业务、长时间高强度持续负载四大关键场景的模拟测试。
写在最后
《银行科技研究社》获悉,在国内存储行业,其实分为纯自研和基于开源组件2个发展阵营。以分布式存储领域为例,曙光等企业是纯自研厂商的代表,产品具有更高的稳定性和性能。
从AI应用方面来说,面对复杂数据处理带来的对存储性能和稳定性的超高要求,坚持纯自研或更有利于推出契合市场需求的产品;从国际竞争力方面来说,纯自研也将推动中国存储在世界上赢得更多关注。
 粤公网安备 44030602000994号
粤公网安备 44030602000994号